RabbitMQ面试常见的一些问题,后续会深入原理,一直保持更新…
MQ的价值是什么
解耦
可扩展性
削峰/高可用
异步通信
RabbitMQ优点有哪些
可靠性: RabbitMQ使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等
灵活的路由 : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起,也可以通过插件机制来实现自己的交换器
扩展性: 多个RabbitMQ节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
高可用性 : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用
多种协议: RabbitMQ除了原生支持AMQP协议,还支持STOMP, MQTT等多种消息 中间件协议。
多语言客户端 :RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等
管理界面 : RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等
令插件机制: RabbitMQ 提供了许多插件 , 以实现从多方面进行扩展,当然也可以编写自 己的插件
RabbitMQ与RocketMQ的比较
总:
RocketMQ商业化的气息更加强,由于阿里的业务特点需要MQ具备极高的吞吐量和消息按序消费,基本上就是翻译了Kafka然后优化其消息按序消费这块。再者,阿里业务很多设计交易,因此对容错性的要求很高,Rocket的核心特点就是大量、按序、容错。
RabbitMQ则是社区氛围很强,各种原生的强大功能(e.g 延迟队列)开箱即用,操作也是很简单便捷。不足之处就是用erlang开发,小团队如果想定制化RabbiMQ的话成本还是很高的。
Rabbit:
AMQP协议,成熟度高;
社区最为活跃,适合小团队开发者进行维护;
自带的功能非常丰富,比如能够直接实现延迟队列效果;
订阅者支持按需获取消息,通过key匹配方式;
对于消息送达时间的定义非常灵活有延迟队列、死信队列等多种队列对时间进行控制;
容错控制最强,死信队列、延迟队列等转为容错而设计;
But
Rabbit不保证多通道下消息按序到达,对于发送到队列或者交换器上的消息,RabbitMQ 不保证它们的顺序;
消息消费后即删除,默认没有持久化机制;
Kafka:
最大的特点就是保证消息的按序到达,Kafka本质上是一个分布式流处理框架,对流式数据的特性有很好的适配;
消息的保留,消息被消费之后还会被保存;
可扩展性最强,生而为大数据;
But
消费者不支持接受指定消息,最细的粒度就是topic级别
Rocket:
基本是用Java翻译了一遍Kafka,所以具备Kafka的主要特性,其中最明显的就是“吞吐量”上面的优势;
除外在阿里的实际需求场景下对RocketMQ做了功能特性上的增加,例如消息的有序性;
重回队列,对于发送失败的消息会进入重回队列
AMQP协议简单概括
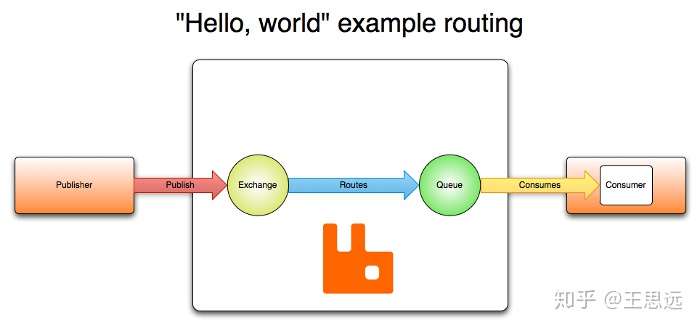
amqp模型主要组成部分有交换机和队列,而者通过路由键(Routing Key)进行转发关联,这个关联的过程叫做绑定(Binding)。生产者向交换机发送消息,交换机根据路由规则将消息转发到对应的队列,消费者则是订阅某个队列消费到达该队列的消息。中间两两之间相互关联的规则在MQ中都是可以自定义的。
amqp协议是一种二进制、长链接、多通道的协议:
二进制:amqp包含五种帧类型,协议头帧、方法帧、内容头帧、消息体帧及心跳帧。方法帧和内容头帧中的内容是人眼不可读的二进制打包数据。而与方法帧和内容头帧不同,在消息体帧内部携带的消息内容没有进行任何打包或编码,可以包含从纯文本到二进制图像数据的任何内容
长连接:建立TCP连接的时候客户端与服务端需要多次交互通信确认一系列参数,例如安全机制、认证机制、帧率等等;结束的时候也需要相互进行close确认
多通道:amqp支持在比较重的TCP/IP连接上建立多个轻量级的连接,通过其Channel类来实现
事务支持
amqp支持两种事务
- 自动事务:每个发布的消息和应答都处理为独立事务.
- 服务端本地事务:服务器会缓存发布的消息和应答,并会根据需要由client来提交它们,需要手动commit
channel.txSelect 用于将当前的信道设置成事务模式
channel . txCommit 用于提交事务
AMQP三层协议
Module Layer:协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
Session Layer:中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
TransportLayer:最底层,主要传输二进制数据流,提供帧的处理、信道服用、错误检测和数据表示等。
RabbitMQ的交换机类型
Direct
一个消息队列使用RoutingKey 绑定到交换器,队列与交换机是n-n的关系。生产者明确消息投递的交换机和队列,消费者明确消费的队列
Fanout
交换机和队列之间没有绑定关系,交换机收到消息时会采用轮询或随即发送到一个队列。采用轮询方式的一个典型应用场景就是削峰,负载均衡
Topic
- 消息队列使用路由规则
P绑定到交换器 - 生产者使用RoutingKey
R发送消息到交换器 - 如果
R 能够匹配 P,则把消息发到该消息队列 - RoutingKey必须由若干个被点
.分隔的单词组成。每个单词只能包含字母和数字。其中\*匹配一个单词,#匹配0个或者多个单词。比如\*.stock.#匹配usd.stock和eur.stock.db但是不匹配stock.nasdaq
topic和direct的区别就是,一条消息可能根据规则发送到多个队列。或者是在服务端业务逻辑中,多个源(业务)的数据需要发送到同一个队列
Headers
- 消息队列使用Header的参数表来绑定。不适用RoutingKey
- 生产者向交换器发送消息,Header中包含了指定的键值对
- 如果匹配,则传给消息队列。
RabbitMQ的队列工作模式
点对点模式
工作队列模式:一个生产者发送消息到队列中,有多个消费者共享一个队列,每个消费者获取的消息是唯一的
发布/订阅模式:往该队列中发布一条消息,订阅了该队列的消费者都能收到
路由模式:与交换机、routing key相配合;消费者只要路由匹配就能收到消息
通配符模式:此模式实在路由key模式的基础上,使用了通配符来管理消费者接收消息。在只用一个队列的情况下可以同时服务很多需求不同的消费者
如何实现延迟队列
- 通过插件
- 通过TTL+死信队列的方式。给消息设置一个过期时间,时间一到就被转发到了死信队列中,消费者消费死信队列中的消息即实现了延迟队列的逻辑
交换器无法根据自身类型和路由键找到符合条件队列时,有哪些处理?
mandatory :true 返回消息给生产者。
mandatory: false 直接丢弃
发送确认机制
生产者把信道设置为confirm确认模式,设置后,所有再改信道发布的消息都会被指定一个唯一的ID,一旦消息被投递到所有匹配的队列之后,RabbitMQ就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一ID),这样生产者就知道消息到达对应的目的地了。
RMQ队列的结构
通常由以下两部分组成:
rabbit_amqqueue_process :负责协议相关的消息处理,即接收生产者发布的消息、向消费者交付消息、处理消息的确认(包括生产端的 confirm 和消费端的 ack) 等
backing_queue:是消息存储的具体形式和引擎,并向 rabbit amqqueue process 提供相关的接口以供调用。
RabbitMQ中消息可能有的几种状态
当消息大量堆积的时候,RMQ会把部分消息进行落盘处理,避免大量消耗内存资源。在发送的时候会优先选择再内存中的资源进行发送(在没设置优先级的情况下)
alpha: 消息内容(包括消息体、属性和 headers) 和消息索引都存储在内存中
beta: 消息内容保存在磁盘中,消息索引保存在内存中。
gamma: 消息内容保存在磁盘中,消息索引在磁盘和内存中都有 。
delta: 消息内容和索引都在磁盘中
导致的死信的几种原因
- 消息被拒(Basic.Reject /Basic.Nack) 且 requeue = false。
- 消息TTL过期。
- 队列满了,无法再添加。
消费者获取消息的几种方式
- 推
- 拉
Reference
https://juejin.cn/post/6844904192146931720
https://jishuin.proginn.com/p/763bfbd2a068
https://zhuanlan.zhihu.com/p/147675691